The Cleaner the Data, the Bigger the Problem
20th April 2026
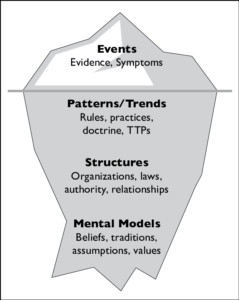
In research, clean data is reassuring.
It suggests clarity. Consistency. Control.
Few outliers. Strong agreement. Smooth patterns.
Everything appears to be working.
In international research, this can be precisely the problem.
When Data Looks Too Good
Clean datasets often signal that respondents:
- understood the question in similar ways
- felt comfortable answering
- stayed within expected boundaries
But across languages and cultures, this kind of consistency is not always natural.
It can indicate something else.
The Hidden Mechanisms Behind “Clean”
In cross-cultural contexts, clean data is often shaped by:
- politeness norms
- preference for moderate responses
- avoidance of contradiction
- shared assumptions embedded in the question
These forces smooth the data.
They reduce variation – not because respondents agree, but because they respond in culturally aligned ways.
Why This Matters
Clean data feels reliable.
It encourages confidence. It supports decisions.
But if the underlying interpretations differ, that confidence is misplaced.
The dataset is consistent, but the meaning is not.
Looking Beyond the Surface
Good international research does not reject clean data.
But it questions it.
It asks:
- what behaviours produced this consistency
- whether agreement reflects alignment or adaptation
- where variation may have been suppressed
At Foreign Tongues, we work with research teams to identify where linguistic and cultural behaviour is shaping the data, especially when everything appears to be working perfectly.
Because in global research, the biggest problems are often the hardest to see.
